整体理解 scrapy是一个爬虫框架,通过它,可以快速构建一个高效且合格的爬虫。
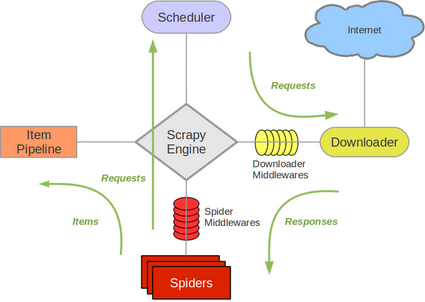
接下来,通过下图理解scrapy框架的组成。
**Scrapy Engine (引擎):**整个爬虫系统的cpu,负责处理所有组件之间的数据流动。
**Spiders(爬虫):**留给用户写代码的地方(接口),一般用户需要写如何发送请求、如何解析响应等。
**Scheduler (调度器):**接收来自引擎发来的请求,将请求放到队列中,并对它们去重。当引擎需要执行一个请求(交给Downloader下载)时,调度器需要从队列中拿出一个任务(链接)给引擎。
**Downloader (下载器):**它唯一的职责就是根据引擎给它的请求,去互联网 (Internet) 上下载网页,然后把下载结果包装成一个响应 (Response) 对象返回给引擎。
Item Pipeline (项目管道) : 数据的“加工厂” 。当 Spider 从网页中提取出数据 (Items) 后,这些数据会被送到这里进行一系列处理,比如:
数据清洗和验证。
丢弃无用的数据。
将最终干净的数据存入数据库、CSV 文件或 JSON 文件中。
Downloader Middlewares (下载器中间件):位于引擎和下载器之间的 “安检通道” 。当请求从引擎发往下载器,以及响应从下载器返回引擎时,都会经过这里。可以用它来:
Spider Middlewares (爬虫中间件) : 位于引擎和 Spider 之间的**“安检通道”**。它主要处理 Spider 的输入(响应)和输出(请求和数据项)。
运作流程 代码写好,程序开始运行…
1 引擎:Hi!Spider, 你要处理哪一个网站?
2 Spider:老大要我处理xxxx.com。
3 引擎:你把第一个需要处理的URL给我吧。
4 Spider:给你,第一个URL是xxxxxxx.com。
5 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6 调度器:好的,正在处理你等一下。
7 引擎:Hi!调度器,把你处理好的request请求给我。
8 调度器:给你,这是我处理好的request
9 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
10 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12 Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13 引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14 管道调度器:好的,现在就做!
基本使用 对于用户来说,在Scrapy的这些组件中,留给用户编写的接口主要是:Spiders、Item Pipeline、Downloader Middlewares。
一般情况下,要使用Scrapy爬取内容,用户需要实现以下3个模块的代码编写:
Spiders (爬虫) : 这是最核心、必须由用户编写 的部分。所有的爬取逻辑,包括从哪个 URL 开始、如何跟踪链接以及如何从页面中提取数据,都在这里定义。
Item Pipeline (项目管道) : 这是第二常用 的用户接口。当从 Spider 中提取出数据(Items)后,如果想进行数据清洗、验证、去重或将其存储到数据库(如 MySQL, MongoDB)等特定地方,就需要自己编写 Pipeline。
Downloader Middlewares (下载器中间件) : 这是非常常用 的用户接口,尤其是在应对反爬虫策略时。你需要通过编写或启用下载器中间件来执行以下操作:
设置随机的 User-Agent。
添加代理 IP。
处理复杂的 Cookie 或 Javascript 逻辑。
使用教程如下:
创建项目 创建一个名为scrapy_tutorial的项目。
1 scrapy startproject scrapy_tutorial
目录结果是这样的。
1 2 3 4 5 6 7 8 9 10 scrapy_tutorial/ scrapy.cfg # 部署配置文件 scrapy_tutorial/ # 项目的Python模块 __init__.py items.py # 定义Item middlewares.py # 定义中间件 pipelines.py # 定义项目管道 settings.py # 设置文件 spiders/ # 放置爬虫的目录 __init__.py
添加代码 往文件spiders/__init__.py中添加代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import scrapyclass QuotesSpider (scrapy.Spider): name = 'quotes' start_urls = [ 'http://quotes.toscrape.com/page/1/' , 'http://quotes.toscrape.com/page/2/' ] def parse (self, response ): page = response.url.split('/' )[-2 ] print ("hello" ) filename = f'quotes-{page} .html' with open (filename, 'wb' ) as f: f.write(response.body) self .log(f'Saved file {filename} ' )
爬取 执行爬虫,scrapy框架回根据输入的quotes(爬虫名字)去爬取数据。
案例爬取:站酷 目标网站:站酷ZCOOL-设计师互动平台-打开站酷,发现更好的设计!
这次爬取的目标是:图片、标题、点赞数、用户名,以用户名、标题、点赞数作为文件夹,将页面内的目标图片爬取下来,放到对应的文件夹内。
初步分析 先不着急写爬虫,先看看有没有需要逆向的参数。
根据抓包,首页的请求标头是这样的,没有加密字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 GET / HTTP/1.1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Accept-Encoding: gzip, deflate, br, zstd Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6 Cache-Control: max-age=0 Connection: keep-alive Cookie: HWWAFSESID=625ae7945294c79738; HWWAFSESTIME=1752131201045; _sm=197f32865943484-051bea0fbaabfd8-4c657b58-1822436-197f3286595616f; meitustat={%22wgid%22:%22197f32865943484-051bea0fbaabfd8-4c657b58-1822436-197f3286595616f%22}; Hm_lvt_e6331320ac7de17020046faecd5fa6b8=1752131201; HMACCOUNT=67DBE82315EBBF65; psid=197f328686a917-0b9d0a9aef36da-4c657b58-1bcee4-197f328686b3a80; sensorsdata2015jssdkchannel=%7B%22prop%22%3A%7B%22_sa_channel_landing_url%22%3A%22%22%7D%7D; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22197f328686e1b39-0af9bfce8e4ade8-4c657b58-1822436-197f328686f35a%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTk3ZjMyODY4NmUxYjM5LTBhZjliZmNlOGU0YWRlOC00YzY1N2I1OC0xODIyNDM2LTE5N2YzMjg2ODZmMzVhIn0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%22197f328686e1b39-0af9bfce8e4ade8-4c657b58-1822436-197f328686f35a%22%7D; newMeitustat_wgid=197f32865943484-051bea0fbaabfd8-4c657b58-1822436-197f3286595616f; customer=2; z_law_undefined=false; session=eyJjdXJyZW50VXNlciI6bnVsbH0=; session.sig=1VmncKqjATz0GMOcrellG1zEeXo; recommend_tip=1; r_drefresh_count=2; Hm_lpvt_e6331320ac7de17020046faecd5fa6b8=1752132340; eventPushTime=1664159429345 Host: www.zcool.com.cn Referer: https://www.zcool.com.cn/home Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: same-origin Sec-Fetch-User: ?1 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0 sec-ch-ua: "Not)A;Brand";v="8", "Chromium";v="138", "Microsoft Edge";v="138" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows"
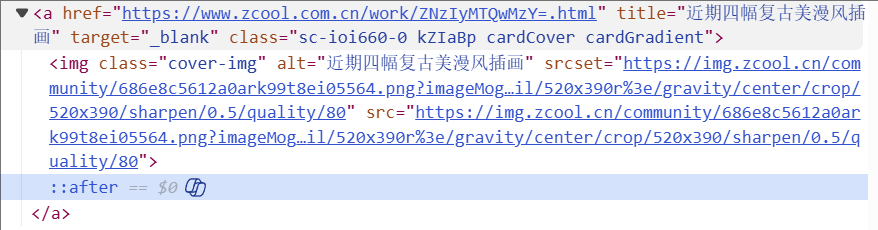
而在返回的页面中,存在指向存放插画具体信息的链接。
但在页面源代码中,并没有类似的内容,大概率是ajax。
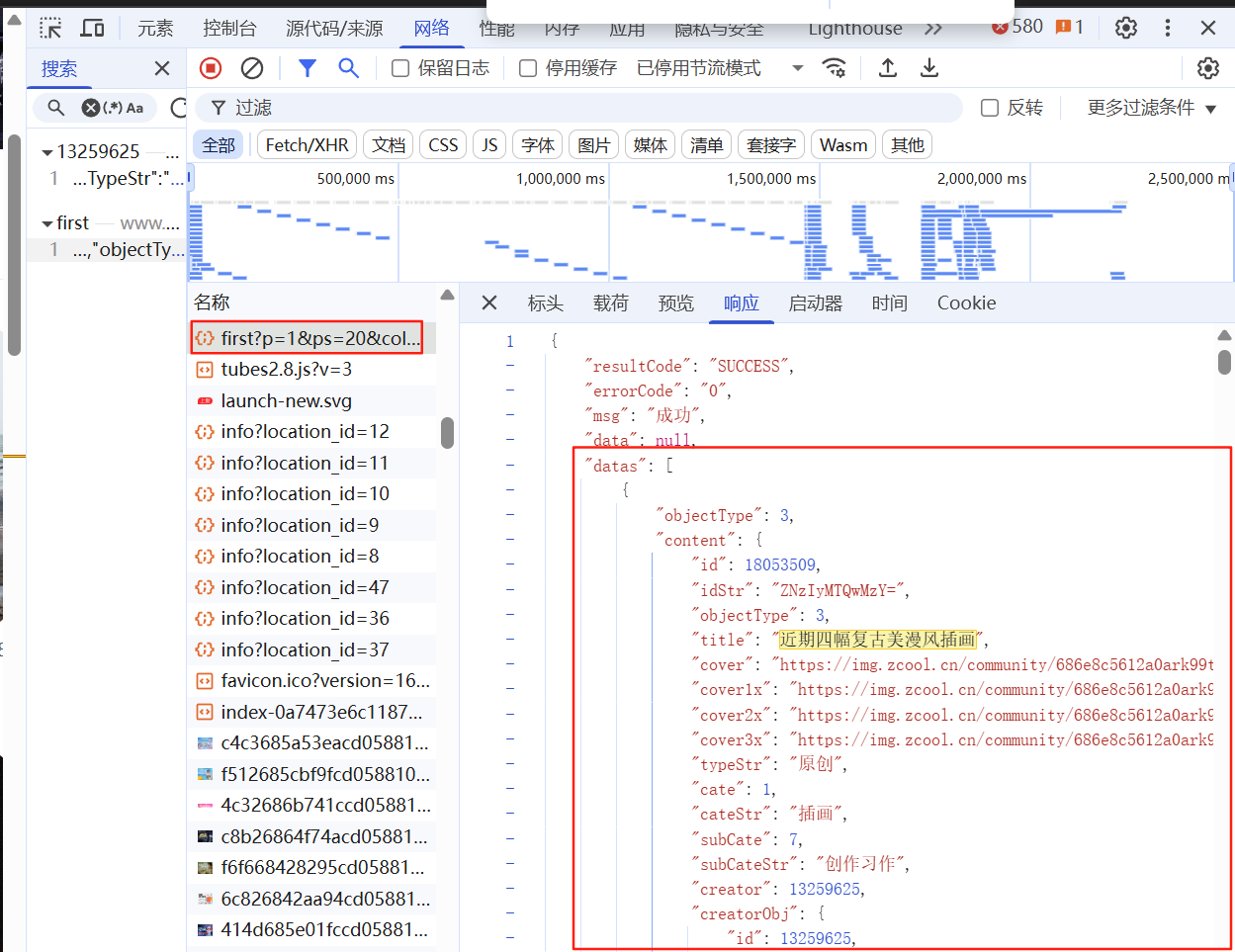
搜索“近期四幅复古美漫风插画 ”,看看哪个请求的响应是这个。
请求参数p=1&ps=20&column=4不像加密,请求头也没有加密字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GET /p1/discover/first?p=1&ps=20&column=4 HTTP/1.1 AbCurrentList: Accept: application/json, text/plain, */* Accept-Encoding: gzip, deflate, br, zstd Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7 Cache-Control: no-cache Connection: keep-alive Cookie: HWWAFSESID=ef49ebbddb7f9f374c; HWWAFSESTIME=1752135440608; _sm=197f369207f2968-0319a2bceab60b8-26011151-1822436-197f3692080551f; meitustat={%22wgid%22:%22197f369207f2968-0319a2bceab60b8-26011151-1822436-197f3692080551f%22}; psid=197f369220f262b-0b4e2b67741871-26011151-1bcee4-197f369221038bb; sensorsdata2015jssdkchannel=%7B%22prop%22%3A%7B%22_sa_channel_landing_url%22%3A%22%22%7D%7D; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22197f36922131c0b-0b4e2b67741871-26011151-1822436-197f36922142e22%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTk3ZjM2OTIyMTMxYzBiLTBiNGUyYjY3NzQxODcxLTI2MDExMTUxLTE4MjI0MzYtMTk3ZjM2OTIyMTQyZTIyIn0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%22197f36922131c0b-0b4e2b67741871-26011151-1822436-197f36922142e22%22%7D; newMeitustat_wgid=197f369207f2968-0319a2bceab60b8-26011151-1822436-197f3692080551f; customer=2; z_law_undefined=false; session=eyJjdXJyZW50VXNlciI6bnVsbH0=; session.sig=1VmncKqjATz0GMOcrellG1zEeXo; z_ex_group=%7B%7D Host: www.zcool.com.cn Referer: https://www.zcool.com.cn/?page=1 Sec-Fetch-Dest: empty Sec-Fetch-Mode: cors Sec-Fetch-Site: same-origin User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 sec-ch-ua: "Not)A;Brand";v="8", "Chromium";v="138", "Google Chrome";v="138" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows"
根据分析,请求参数p=1指的页数为1;ps未知,但ps是不变的,大概率无关紧要;column=4指的是展示的页面中,一行4个item。
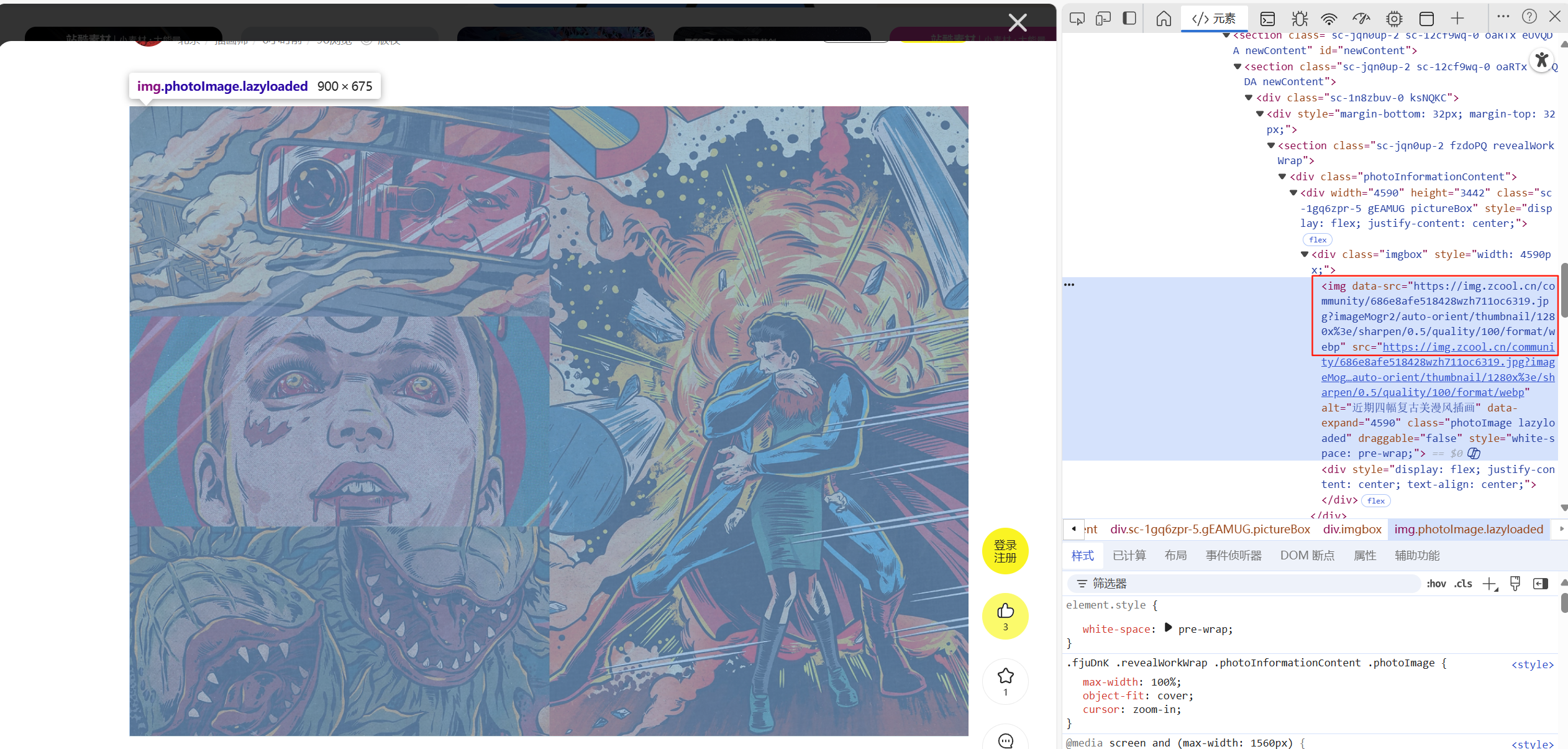
接下来,打开具体的作品链接搜集信息,发现页面内 无法使用F12(开发者工具),也无法右键获得图片的链接地址。
然而,在搜索栏 中,可以打开开发者工具。
请求的链接是一个静态页面,这回不涉及ajax了,真好。
同时,这个请求标头同样没有加密字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GET /work/ZNzIyMTQwMzY=.html HTTP/1.1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Accept-Encoding: gzip, deflate, br, zstd Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6 Cache-Control: max-age=0 Connection: keep-alive Cookie: HWWAFSESID=625ae7945294c79738; HWWAFSESTIME=1752131201045; _sm=197f32865943484-051bea0fbaabfd8-4c657b58-1822436-197f3286595616f; meitustat={%22wgid%22:%22197f32865943484-051bea0fbaabfd8-4c657b58-1822436-197f3286595616f%22}; Hm_lvt_e6331320ac7de17020046faecd5fa6b8=1752131201; HMACCOUNT=67DBE82315EBBF65; psid=197f328686a917-0b9d0a9aef36da-4c657b58-1bcee4-197f328686b3a80; sensorsdata2015jssdkchannel=%7B%22prop%22%3A%7B%22_sa_channel_landing_url%22%3A%22%22%7D%7D; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22197f328686e1b39-0af9bfce8e4ade8-4c657b58-1822436-197f328686f35a%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTk3ZjMyODY4NmUxYjM5LTBhZjliZmNlOGU0YWRlOC00YzY1N2I1OC0xODIyNDM2LTE5N2YzMjg2ODZmMzVhIn0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%22197f328686e1b39-0af9bfce8e4ade8-4c657b58-1822436-197f328686f35a%22%7D; newMeitustat_wgid=197f32865943484-051bea0fbaabfd8-4c657b58-1822436-197f3286595616f; customer=2; z_law_undefined=false; session=eyJjdXJyZW50VXNlciI6bnVsbH0=; session.sig=1VmncKqjATz0GMOcrellG1zEeXo; r_drefresh_count=1; Hm_lpvt_e6331320ac7de17020046faecd5fa6b8=1752131669; recommend_tip=1 Host: www.zcool.com.cn Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: same-origin Sec-Fetch-User: ?1 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0 sec-ch-ua: "Not)A;Brand";v="8", "Chromium";v="138", "Microsoft Edge";v="138" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows"
利用scrapy框架写爬虫 在文件夹spiders的__init__.py中。
将默认的start_urls换成函数start_requests。
1 2 3 4 5 6 7 8 9 10 11 12 num_pages = 1 page_url = "https://www.zcool.com.cn/p1/discover/first?p=XXX&ps=20&column=4" def start_requests (self ): for i in range (1 , self .num_pages + 1 ): yield scrapy.Request(url=self .page_url.replace("XXX" , str (i)), callback=self .parse)
简单的伪装一下headers,在文件settings.py中,修改成下面的语句。
1 2 3 4 DEFAULT_REQUEST_HEADERS = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36" }
下面插入一个小插曲,之前没分析出ajax的时候做的一些操作。
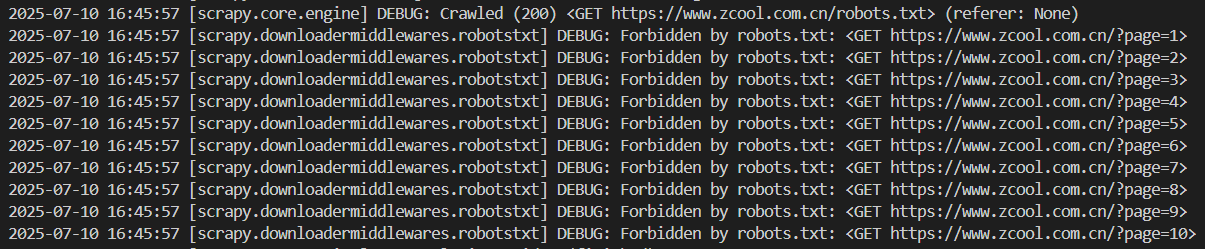
为了防止出现下面这个情况,还需要修改设置。(我之前爬主页的截图)
在settings.py中,修改ROBOTSTXT_OBEY。
这回没问题了,接下来定位首页的每个Item。
回到正轨继续分析,修改请求链接后能访问到目标链接了。
收集pageUrl。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def parse (self, response ): """ 解析列表页的JSON,为每个作品生成一个详情页的抓取请求。 """ try : data = response.json() except json.JSONDecodeError: self .logger.error(f"Failed to decode JSON from {response.url} " ) return if data and data.get('datas' ): for item in data['datas' ]: content = item.get('content' ) if not content: continue page_url = content.get('pageUrl' ) if page_url and '/work/' in page_url: creator_obj = content.get('creatorObj' , {}) title = content.get('title' , '无标题' ) username = creator_obj.get('username' , '匿名用户' ) recommend_count = content.get('recommendCount' , 0 ) yield scrapy.Request( url=page_url, callback=self .parse_work_details, cb_kwargs={ 'title' : title, 'username' : username, 'recommend_count' : recommend_count } )
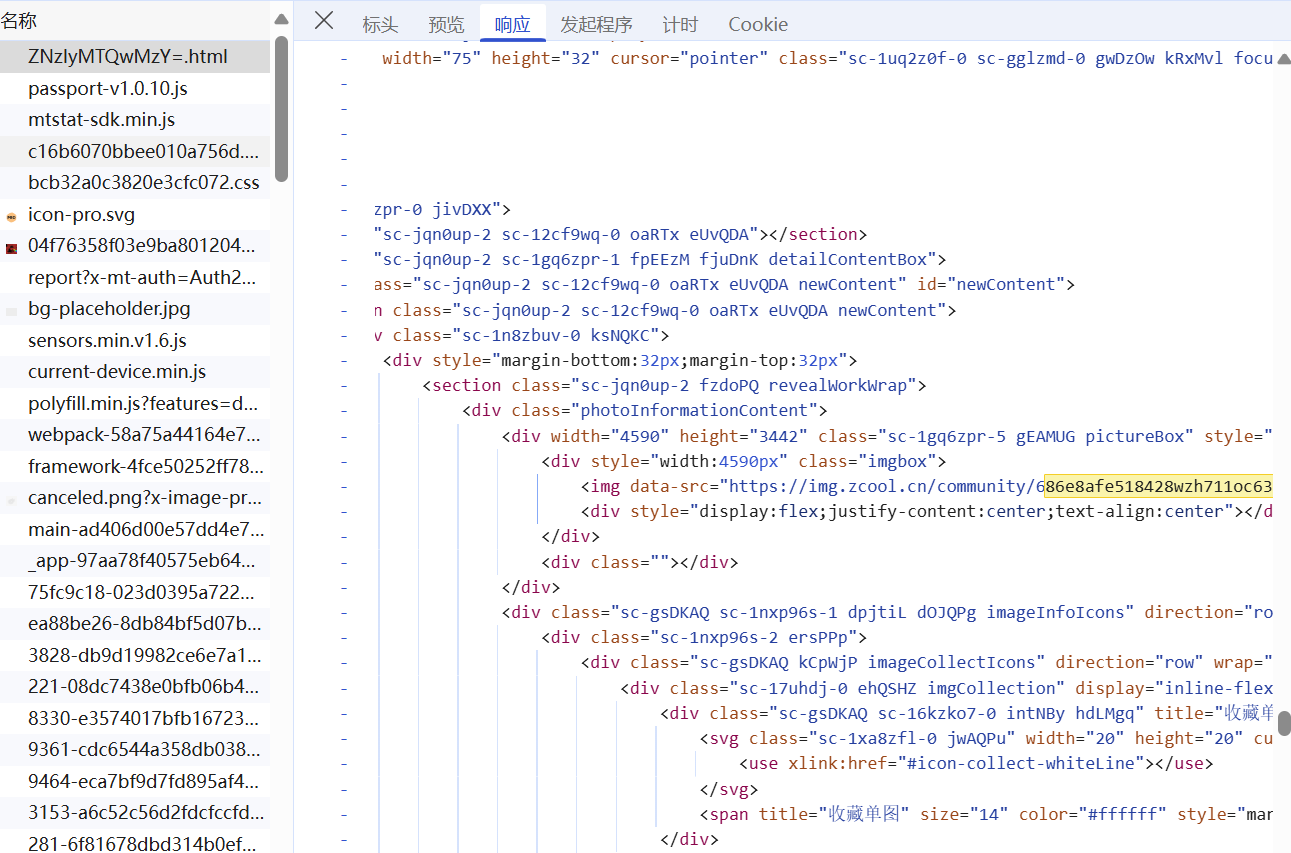
针对pageUrl返回的页面,需要用另一个parser来解析,用来定位图片链接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def parse_work_details (self, response, title, username, recommend_count ): self .logger.info(f"Parsing details for: {title} " ) json_data_string = response.css('script#__NEXT_DATA__::text' ).get() image_urls = [] if json_data_string: try : data = json.loads(json_data_string) product_images = data.get('props' , {}).get('pageProps' , {}).get('data' , {}).get('productImages' , []) image_urls = [img.get('url' ) for img in product_images if img.get('url' )] print (f"Found {len (image_urls)} images for {title} by {username} " ) except json.JSONDecodeError: self .logger.error(f"Failed to parse JSON from page: {response.url} " ) if image_urls: clean_title = re.sub(r'[\\/*?:"<>|]' , "" , title).strip() clean_username = re.sub(r'[\\/*?:"<>|]' , "" , username).strip() folder_name = f"{clean_title} -{clean_username} -{recommend_count} 赞" yield { 'image_urls' : image_urls, 'folder_name' : folder_name } else : self .logger.warning(f"No images found on page: {response.url} " )
函数parse_work_details会为管道带来图片链接、文件夹名字。
接下来在管道类中,写对图片链接的处理方式。
定义了一个新类ZcoolImagePipeline,继承ImagesPipeline——ImagesPipeline是Scrapy专门爬图片的类,所以这里覆写函数get_media_requests和file_path,自己定义对图片的处理逻辑即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class ZcoolImagePipeline (ImagesPipeline ): def get_media_requests (self, item, info ): for i, image_url in enumerate (item.get('image_urls' , [])): print (f"Requesting image {i} from URL: {image_url} " ) yield scrapy.Request(image_url, meta={'item' : item, 'image_index' : i}) def file_path (self, request, response=None , info=None , *, item=None ): image_item = request.meta['item' ] image_index = request.meta['image_index' ] folder = image_item['folder_name' ] file_extension = os.path.splitext(urlparse(request.url).path) if not file_extension: file_extension = '.jpg' return f'{folder} /{image_index} {file_extension} '
如果使用了ImagesPipeline,还需要再Setting中定义刚才的管道类和存储路径。
1 2 3 4 5 6 7 8 ITEM_PIPELINES = { "zcool.pipelines.ZcoolImagePipeline" : 100 , } IMAGES_STORE = "C:\\Users\\19415\\Desktop\\爬虫\\Scrapy_Projects\\zcool\\downloads"
跑结果!跑不出来,做了好久的检查,代码没问题,最后看日志,发现ImagesPipeline需要按照Pillow。
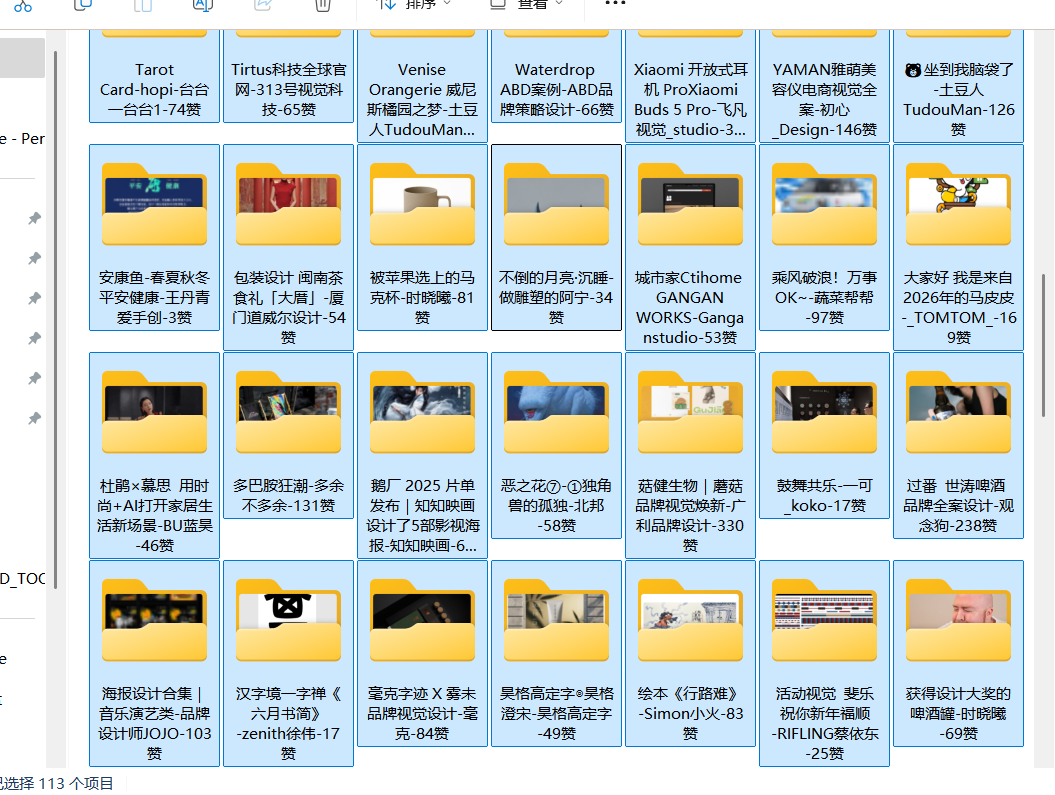
重新启动!
这回完美了,下载到了很多图片。
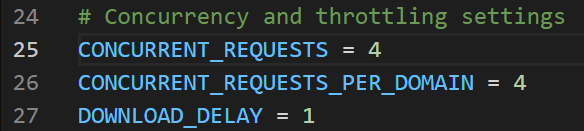
如果爬取太慢,可以设置一下这个。
最后,申明一下,只是做一个爬虫学习!不是想引起DDoS攻击!侵权删!!