协程 简单来说,协程可以把同步操作变成异步操作。
比方说,在写爬虫时,发送请求和等待回应会触发IO堵塞,如果是同步操作,线程就会一直等;而如果是异步操作,线程会切换到其它任务执行,而不是“闲等”。
常见的requests.get是同步操作,如果想切换成异步,需要安装aiohttp。
除此之外,关于一些其它的io操作也可以用协程,如:读写文件。
关于python的asyncio的实现,其实就是使用select、poll、epoll等机制,监控文件描述符的状态,避免线程堵塞。
自Java21起,虚拟线程就是Java的协程实现。
协程可以极大的提高爬取的速率。
爬取壁纸 我在网上找了一个壁纸网站。
https://haowallpaper.com
尝试用多线程、协程的方式,去爬取壁纸。
单线程的爬取流程如下:
解析每一页中,所有图片所在的子链接;
获取子链接中,图片的下载链接;
下载图片。
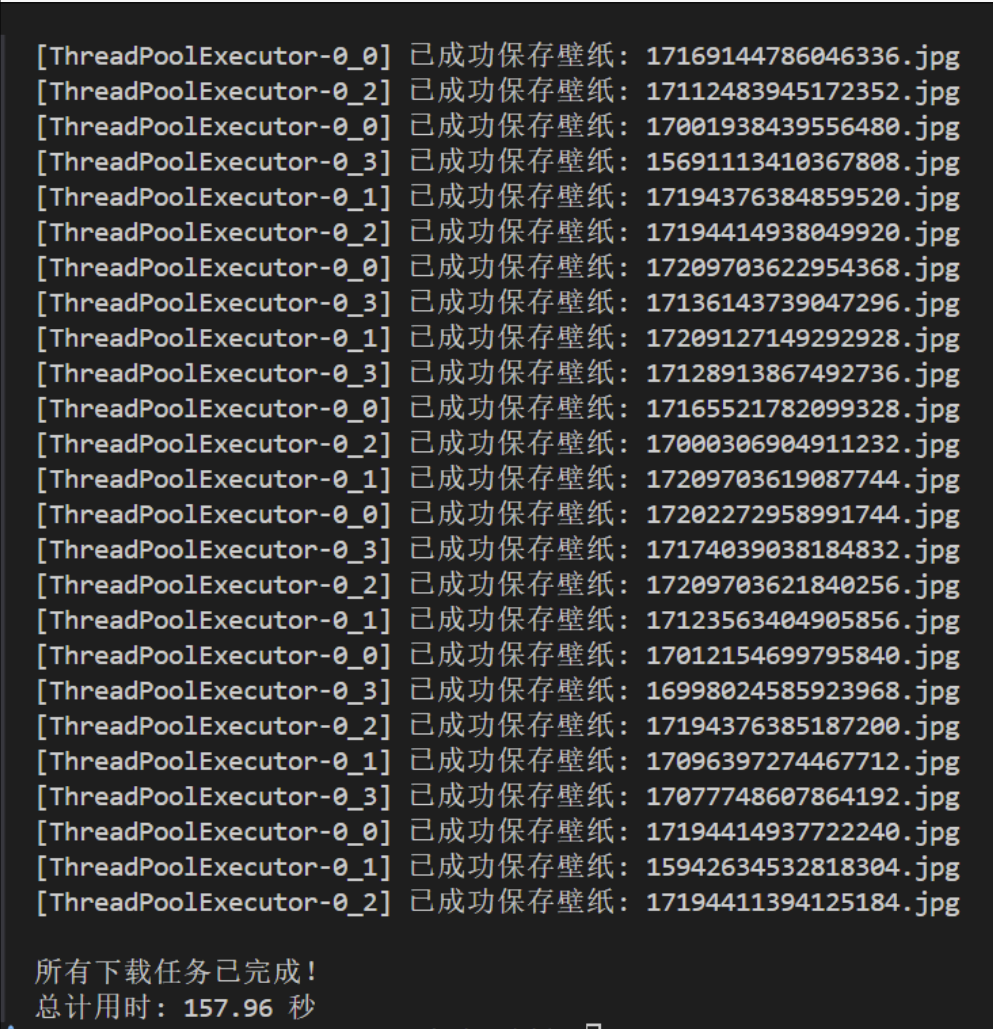
在单线程的代码基础上把代码改成多线程,再将子链接分配给了具有4个线程的线程池,90张图片,花了将近160s。
1 2 3 4 5 6 7 8 9 10 11 12 with concurrent.futures.ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: future_to_url = {executor.submit(download_image, link): link for link in all_links} for future in concurrent.futures.as_completed(future_to_url): url = future_to_url[future] try : result = future.result() except Exception as exc: print (f"链接 {url} 的任务执行时产生了一个异常: {exc} " )
之所以如此之慢,因为每个线程在下载一个图片时,线程会等待I/O设备接收完图片,再进行下一步处理。(I/O堵塞)。
可以把协程视作I/O多路复用的高级实现,每一个被async修饰的地方,相当于一个被监听描述符。
在I/O堵塞时,使用协程的方式编程,线程便可以去做别的事情。比如:在下载图片时,线程能够切换任务,去发送另一个图片下载请求,这样一来,在同一时间内,这些图片同时下载,便可以节约大量时间。
在python中,要使用协程,在定义函数时、异步资源请求要使用async,而等待结果用await。
下面的代码仅供参考。
asyncio.gather:可以接收1个或多个对象,然后放入事件循环中运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 async def download_image_async (session: aiohttp.ClientSession, sub_link: str ): """ (异步) 工作协程,用于从给定的子链接下载单张图片。 Args: session (aiohttp.ClientSession): aiohttp的会话对象. sub_link (str): 壁纸详情页的相对路径. """ try : filename = sub_link.split('/' )[-1 ] + ".jpg" filepath = os.path.join(OUTPUT_DIR, filename) if os.path.exists(filepath): return f"已存在: {filename} " full_url = BASE_URL + sub_link async with session.get(full_url, timeout=15 ) as response: response.raise_for_status() html_content = await response.text() soup = BeautifulSoup(html_content, 'html.parser' ) meta_tag = soup.find('meta' , attrs={"property" : "og:image" }) if not meta_tag or not meta_tag.get('content' ): return f"未找到链接: {sub_link} " img_url = meta_tag.get('content' ) async with session.get(img_url, timeout=30 ) as img_response: img_response.raise_for_status() image_data = await img_response.read() async with aiofiles.open (filepath, "wb" ) as f: await f.write(image_data) return f"成功: {filename} " except asyncio.TimeoutError: return f"超时错误: {sub_link} " except aiohttp.ClientError as e: return f"网络错误: {sub_link} - {e} " except Exception as e: return f"未知错误: {sub_link} - {e} " async def download_batch_async (links_batch: List [str ] ): """ (异步) 创建一个 aiohttp 会话并并发执行一批下载任务。 """ async with aiohttp.ClientSession(headers=HEADERS) as session: tasks = [download_image_async(session, link) for link in links_batch] results = await asyncio.gather(*tasks, return_exceptions=True ) success_count = sum (1 for r in results if isinstance (r, str ) and r.startswith("成功" )) exist_count = sum (1 for r in results if isinstance (r, str ) and r.startswith("已存在" )) fail_count = len (results) - success_count - exist_count print (f"本批次处理完成 - 成功: {success_count} , 已存在: {exist_count} , 失败: {fail_count} " ) def run_thread_worker (links_batch: List [str ] ): """ (同步) 每个线程的入口函数。 它会创建一个新的 asyncio 事件循环来运行分配给它的那批下载任务。 """ loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) loop.run_until_complete(download_batch_async(links_batch)) loop.close()
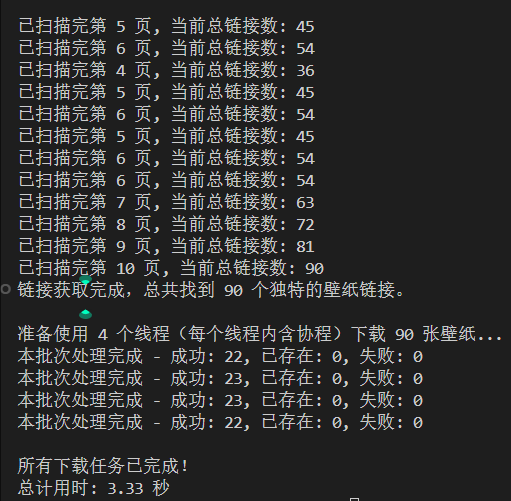
在加了协程后,任务会完成得非常快。
我还做了个小实验,用“纯多线程”和“多线程 & 单一协程”两种结构进行爬取,在这样的设置下,哪个下载速度会更快?(这里的后者含义是:每个线程只有一个协程)
答案是后者,来看看大模型给出的理由。
大致意思是:由于图片很小,本来一下子就能下载完,但普通的多线程下载涉及到I/O堵塞,线程/进程会被操作系统加入到堵塞线程队列中,然后操作系统会去执行其它的线程/进程,等待I/O设备的唤醒和操作系统的下一次调度;而在“多线程 & 单一协程”的模式中,线程并没有被堵塞,而是会去执行事件循环,等到操作系统的通知——监听的事件是否完成,如果完成则立即处理。
最后,看看壁纸!